RocksDB概述
LSM 类存储引擎、数据库之一。所谓LSM,一般的名字叫 Log Structured-Merge Tree(日志结构合并树),来源于分布式数据库领域,也是BigTable 的论文中所使用的文件组织方式。它的特点在于写入的时候是append only的形式,就像名字所显示的那样,跟日志一样只在文件后面追加。
LSM 树结构的问题: 写入速度快,读取速度慢,写放大和读放大都较高。
Rocksdb本身支持单个kv的读写和批量kv值的读写。由于LSM的出身,它专注于利用LSM树的特性,适应有序、层次化的磁盘读写。在LSM树之上构建了Rocksdb,而在RocksDB之上同样有一些更面向应用层的数据库,包括分布式数据库、查询引擎、大数据存储引擎、图数据库如Janusgraph等。
1. RocksDB 的读写层次和数据结构
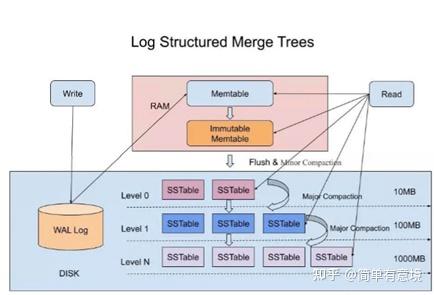
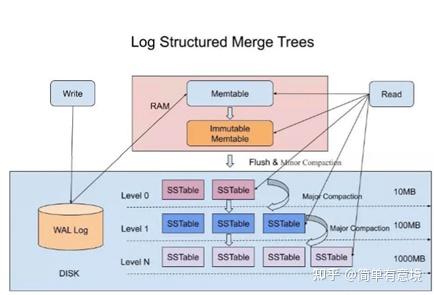
rocksdb的数据写入结构如下:
在内存有memtable,
磁盘有WAL文件目录和SST文件目录。
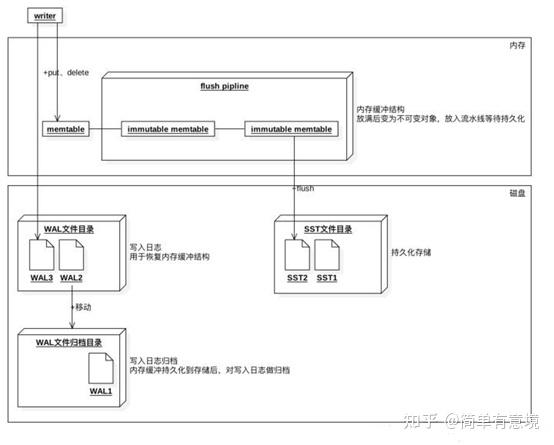
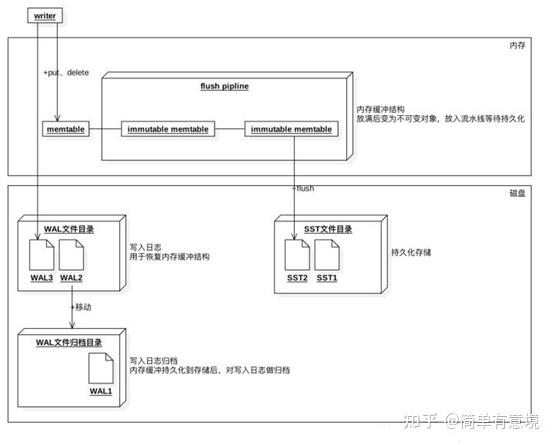
memtable和SST文件
内存中的数据和SST文件组成了RocksDB数据的全集。
rocksdb中的数据结构有三种,分别是skiplist、hash-skiplist、hash-linklist;跟leveldb不同。跳表的好处在于插入的时候可以保证数据的有序,支持二分查找、范围查询。当然,删除的时候不是立即删除,因为会影响到数据的写放大,一般是在compact阶段进行真正的删除。
hash-skiplist的索引既有hash索引,又有skiplit的二分索引,针对于有明确key或教完整key前缀的查询,如果要进行全表扫描,会非常耗费内存及低性能,因为要产生临时的有序表; hash-linklist也是一样的道理。
对于hash-skiplist, 读取时候的缓存分片如下:
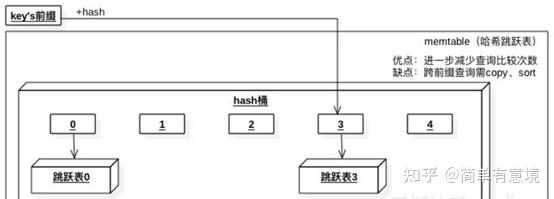
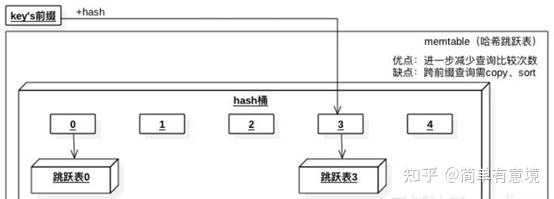
SST文件结构类型
SSTable是一种数据结构,当memtable达到一定上限之后,会flush到disk形成immutable Sorted String Table (SSTable);Rocksdb写入数据,即put的时候,在磁盘中保存level层次树,在单个level中超出大小的时候进行合并;合并的时候是支持多线程并发的;
紧凑compact操作
compact,紧凑,可译作压缩。
为了提高读性能,一般会做compact操作。compact操作将数据根据key进行合并,删除了无效数据,缩短了读取路径,优化了范围查询。
把内存里面不可变的Memtable给dump到到硬盘上的SSTable层中,叫做minor compaction。
SStable里的合并称为major compaction。由于major compaction耗费CPU和磁盘性能,HBase中需要在高峰时段禁用major compaction。
写放大:一份数据被顺序写几次(还是那一份数据,只是需要一直往下流)。第一次写到L0,之后由于compaction可能在L1~LN各写一次
读放大:一个query会在多个sstable,而这些sstable分布在L0~LN
空间放大:一份原始数据被copy/overwritten(一份用于服务query,一份用于snapshot之后用于compaction)
下面是一些典型的Compaction技巧,可以看到,没有写放大,读放大,空间放大三者都很完美的方案:
Leveled Compaction
- 全部层级都按照标准的从上到下进行层级合并
- 读写放大都比较严重,但是空间放大较低
- 在这篇论文(Towards Accurate and Fast Evaluation of Multi-Stage Log-Structured Designs)中有详细的阐述
Tiered Compaction
- 即 RocksDB 中的 Universal Compaction
- 空间放大和读放大严重,但是写放大最小
- 在这篇论文(Dostoevsky: Better Space-Time Trade-Offs for LSM-Tree Based Key-Value Stores via Adaptive Removal of Superfluous Merging)有详细的阐述
Tiered+Leveled Compaction
- 即 RocksDB 中的 Level Compaction
- 是一个混合的 Compaction 策略,空间放大比 Tiered Compaction 更低,写放大也比 Leveled 低
Leveled-N Compaction
- 比 Leveled Compaction 写放大更低,读放大更高
- 一次合并 N - 1 层到第 N 层
2. 分布式Rocksdb的改造
Read-Only模式下可以读取数据,但是数据并不一定是最新的;Read Secondary Instance模式下可以读到最新的数据,实现方式是redo WAL(重放日志);
可用性
多节点下可用性比较重要;一般是通过WAL实现重放,但是WAL仍然会遇到磁盘损坏的问题。常用的,拍脑门能想出来的解决方式是增加数据一致性的模块;
数据一致性
分布式数据库的一致性协议需要共识协议作为基础,rocksdb之上加入一层raft协议可以实现分布式一致性,实现该协议也是为了尽可能地提高可用性,尽管在系统陷入到节点数超过一半挂掉的情况是无法保证完好的一致性的。
但是这样子会加深写放大的问题。对此可以使用写放大较低的compact策略缓解;对于系统层面,如果不想写放大太多,也可以减少raft写及数据备份,直接将读节点的比例增加。(都不是完美的方案)
事务处理
在分布式数据库中自然而然会遇到事务的处理,2pc协议是分布式事务的一个解决方案;但是存在性能不够好,单点故障的问题,宕机导致数据不一致的问题;实际使用中,常使用XA协议,采用2PC两段式提交作为基础,是X/Open DTP组织(X/Open DTP group)定义的两阶段提交协议。
高层应用对Rocksdb的封装
- MVCC
对于DBMS来说,常用到MVCC进行并发情况下的快速读写和隔离,MVCC会需要扫描同一个key下多个timestamp下的值,但是由于LSM的特性,SCAN操作的时候每个key可能出现在SSTable的任意层次,所以读放大明显。一般采用bloom filter降低IO读写次数,但是在长key造成很大的key空间的情况下,这种方法也捉襟见肘。CockroachDB采用了prefix 前缀bloom filter来缓解这个问题。
2. Backwards iteration
后向遍历在其他key-value db上一般效率比forward iteration慢,但是Rocksdb有对其进行优化。
3. Graph Database
图数据库Dgraph利用Rocksdb作为(Predicate, Subject) --> PostingList的Key-Val存储,即图中的一个有向边。其次,利用Rocksdb的单key随机读写性能,建立PostingList的索引。
3. Rocksdb可以改进的问题
读写放大严重;
应对突发流量的时候削峰能力不足;
压缩率有限;
索引效率较低;
scan效率慢;